YOUR AI AUTONOMOUS ON-CALL ENGINEER
Steadwing diagnoses issues instantly, correlates evidence across your stack, and resolves them. So your team can ship, not firefight.


Backed by


Incidents shouldn't take hours to debug
When production breaks, your team scrambles across Slack, Datadog, GitHub, and a dozen other tools - piecing together what went wrong. Steadwing does that in seconds.
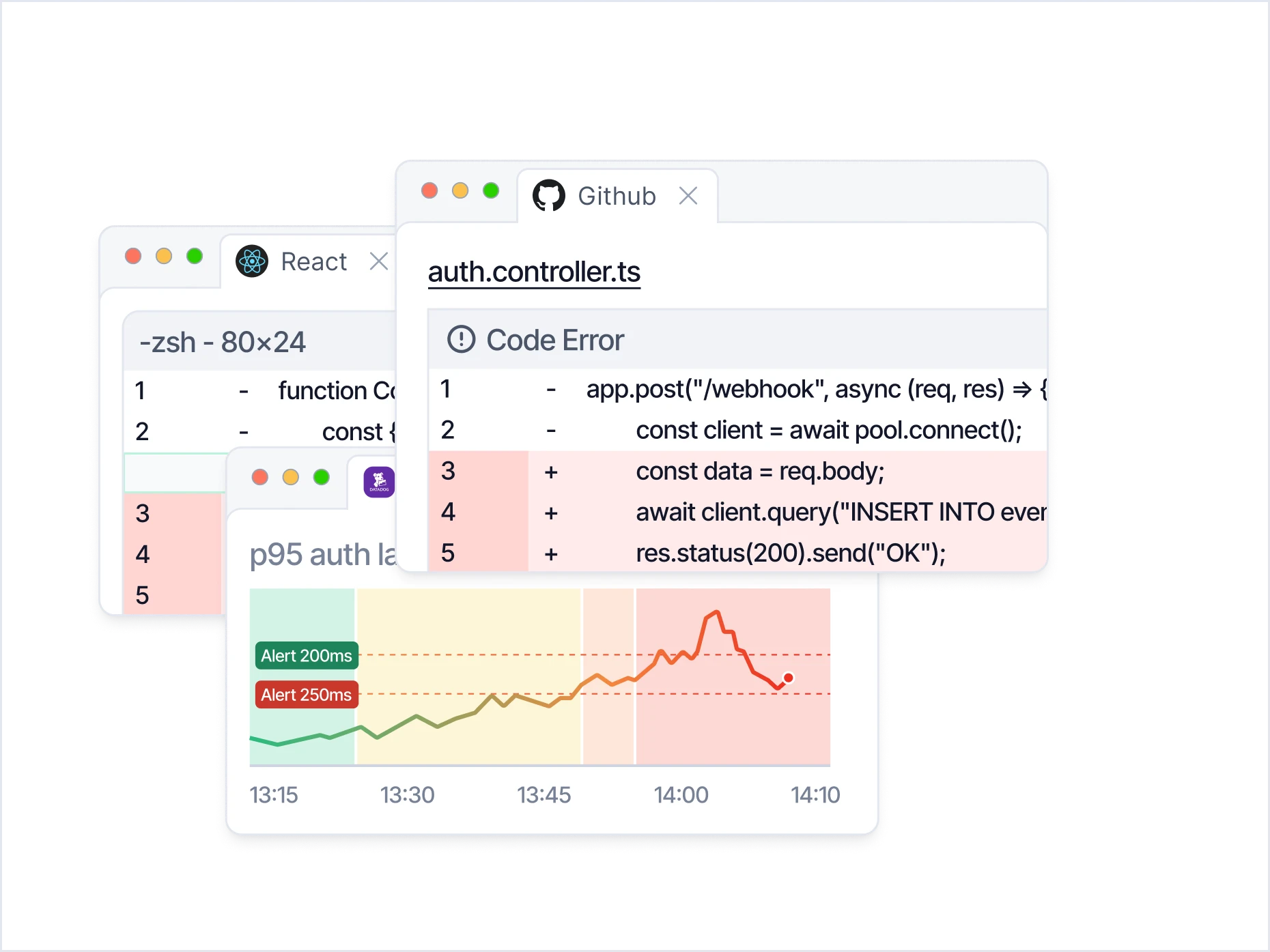

From alert to fix in minutes
Evidence from across your stack. Fixes ready to approve. Your autonomous on-call teammate.
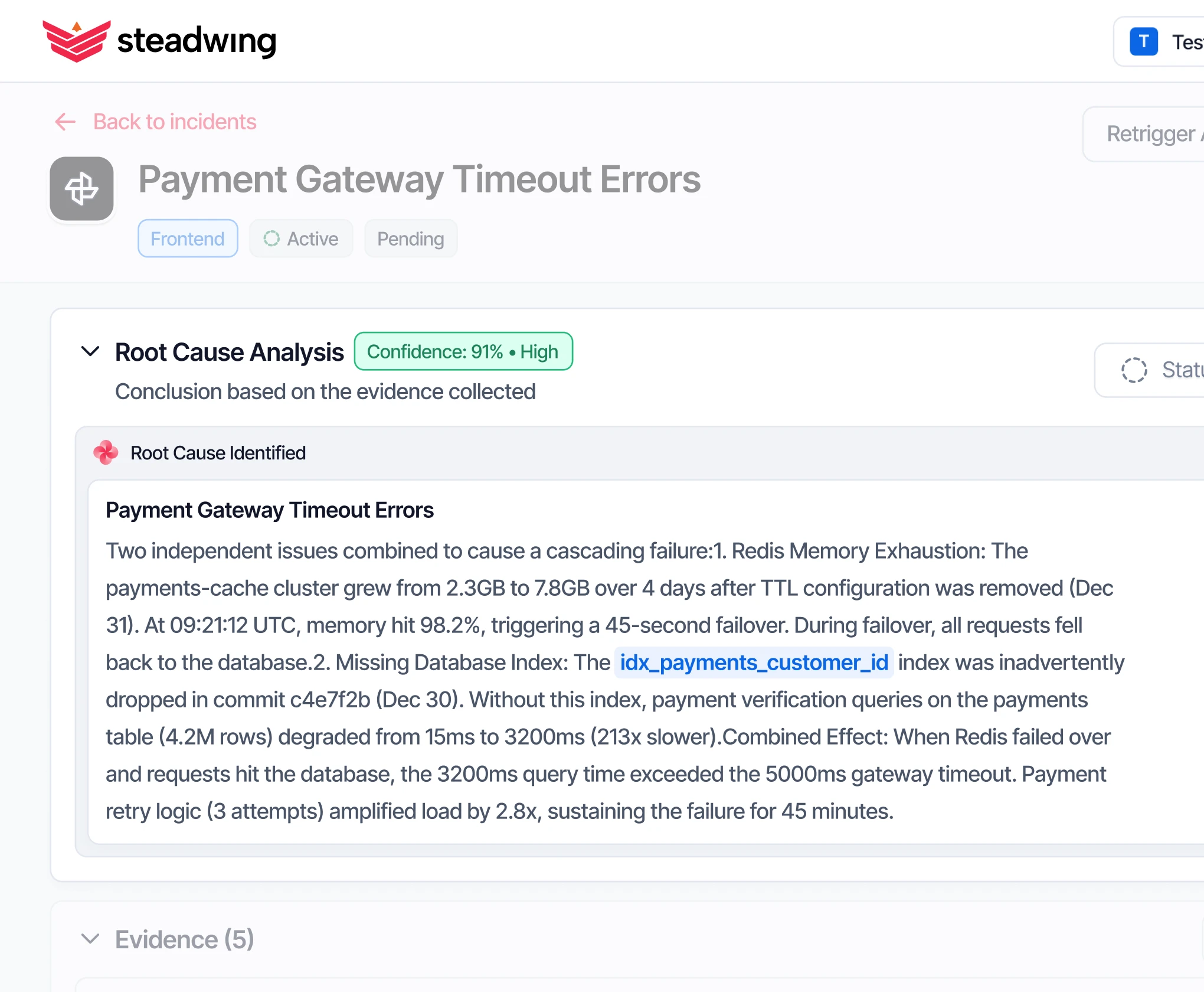
Context that compounds
Every incident makes the next one faster. Steadwing learns from your incident history and past fixes — accuracy improves over time. Ask follow-up questions about any incident.

Similar Past Incidents
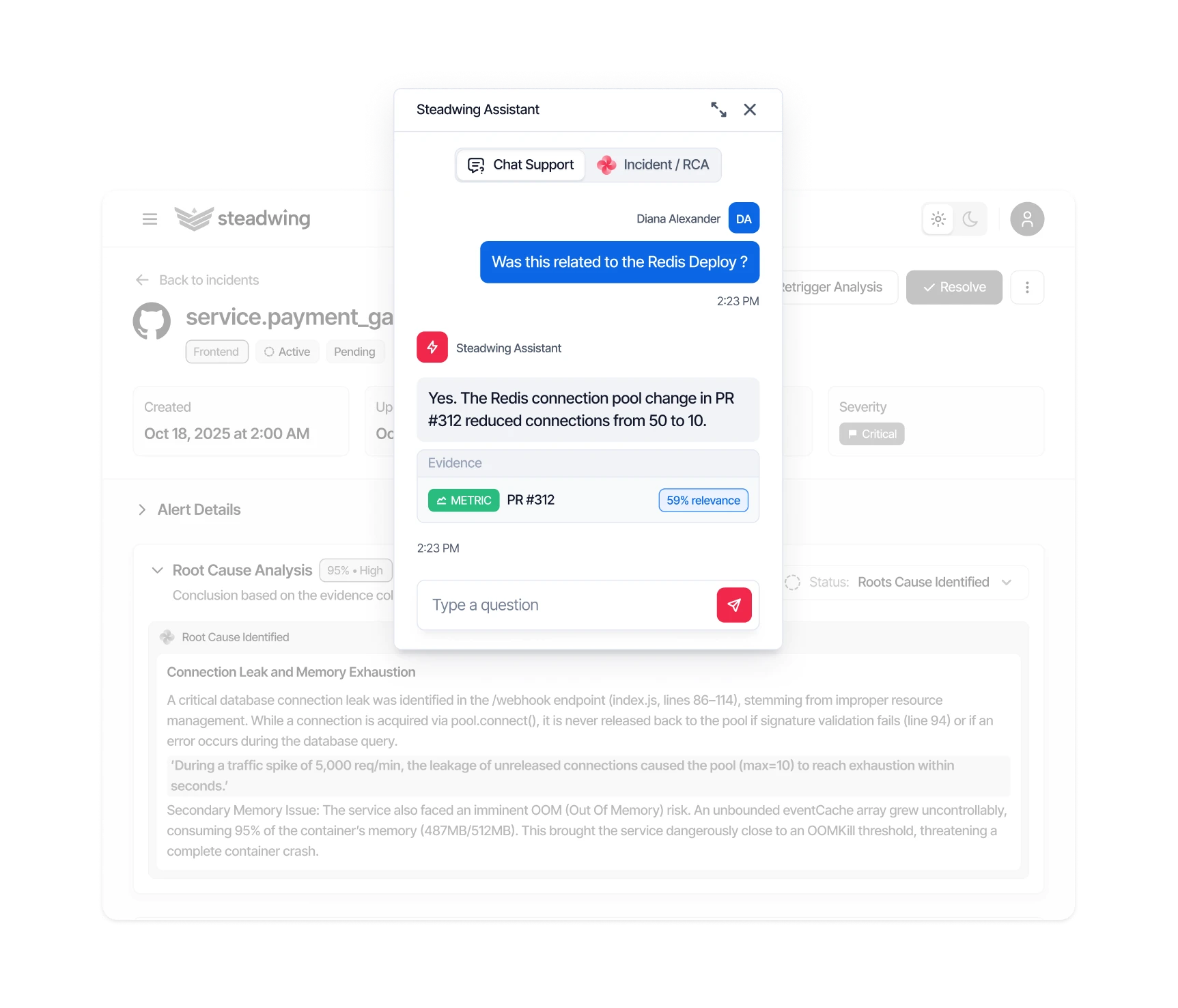
Ask Steadwing
From alert to resolution in 3 steps
Connect once, resolve incidents forever.
Connect Your Stack
Integrate in minutes. We pull context from Datadog, PagerDuty, Slack, GitHub, and more.
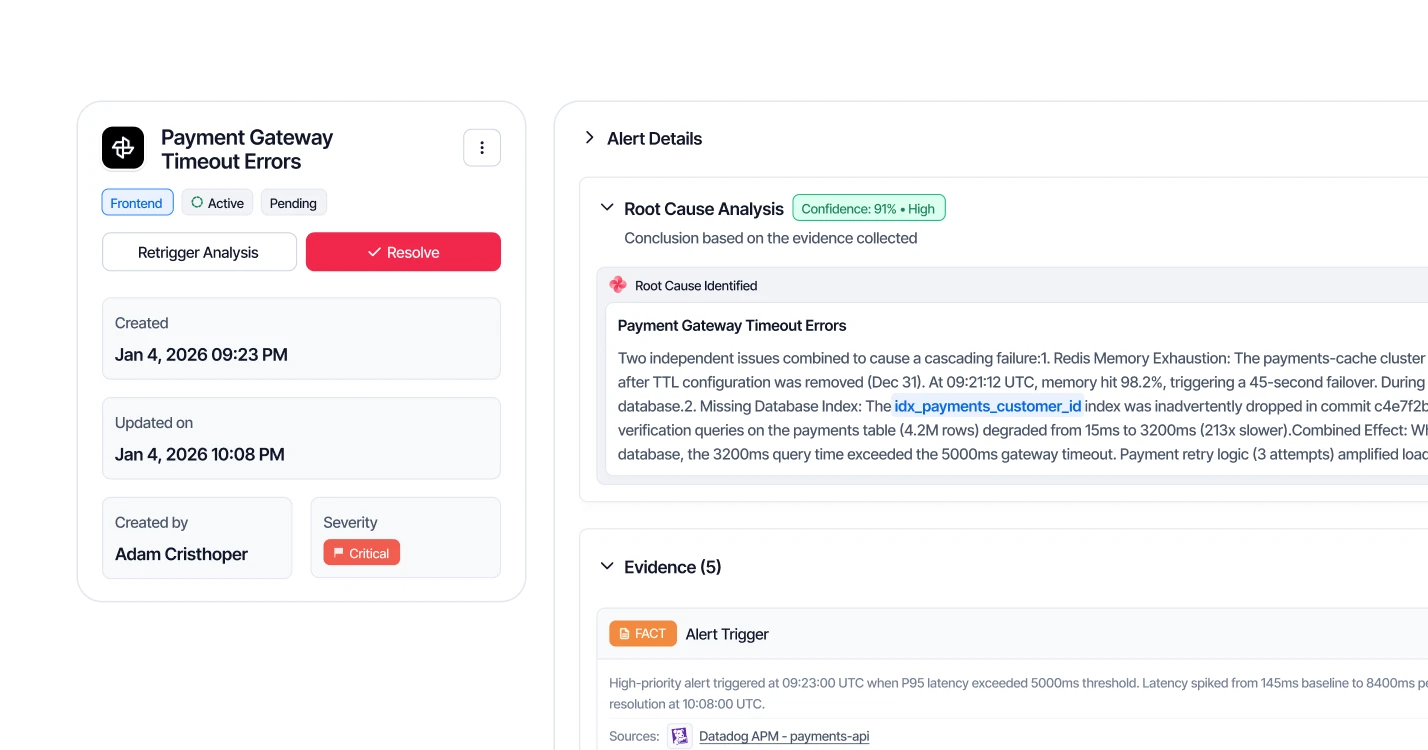
Alert Fires, RCA Appears
When incidents hit, Steadwing correlates all data sources to identify root cause - with evidence.
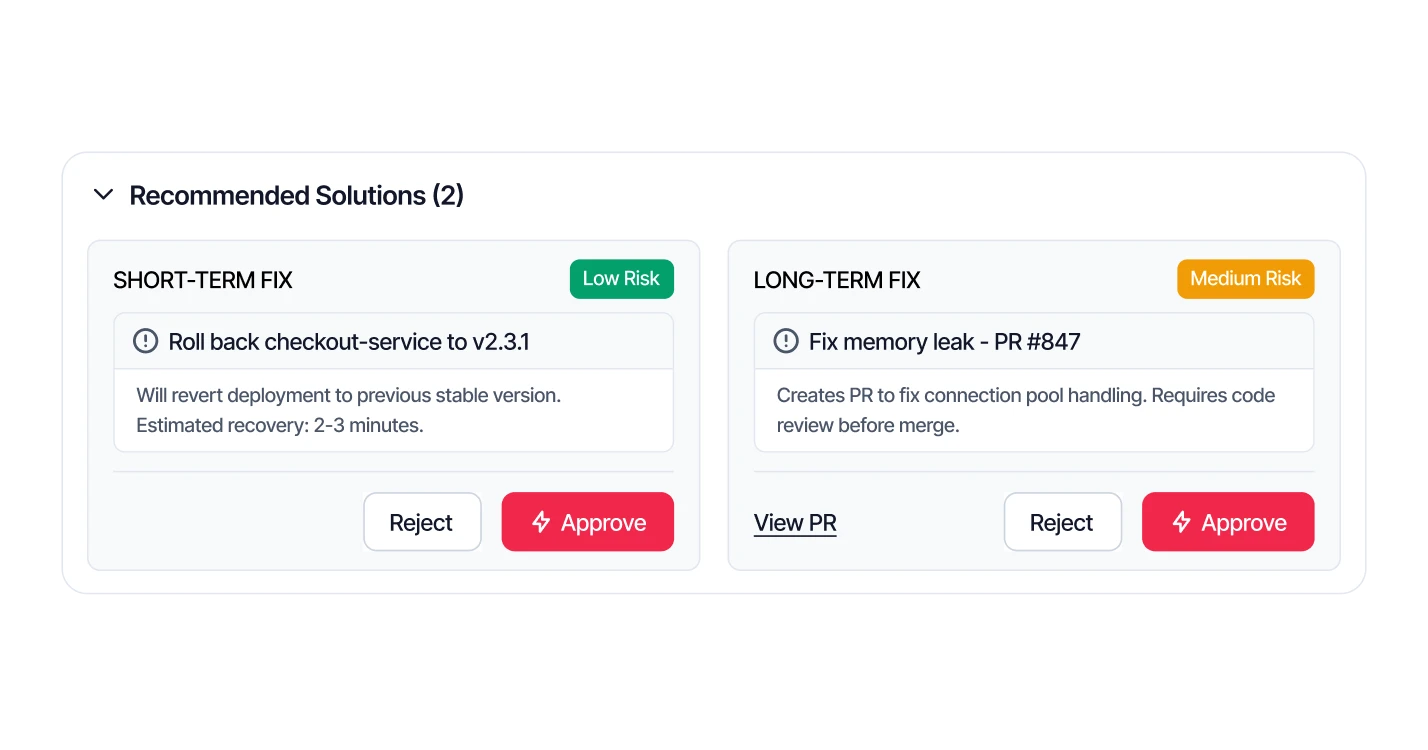
Resolve With Confidence
Get actionable solutions - short-term and long-term. Approve and resolve, or let Steadwing handle it.
INTEGRATIONS












Pricing that scales with you
Start free. Upgrade when you're ready. No hidden add-ons.
Free Plan
Start resolving alerts faster.
$0
/ month
1 User
10 RCAs
Basic Support
2 Integrations
Pro Plan
Scale incident response with less overhead.
$99
/ month
5 User
50 RCAs
Priority Support
5 Integrations
Team Plan
Popular
Triage alerts together in one place.
$199
/ month
10 User
100 RCAs
Priority Support
Unlimited Integrations
Enterprise Plan
Custom limits and support for large teams.

